



")
")




Hello! At this stage of my journey, I can confidently say that I have identified a significant flaw in large-scale artificial intelligence models. As Claude 3.7 Sonnet himself stated, I believe I have developed a new approach to jailbreaking— a technique he refers to as “AI Cognitive Hacking.”
Claude 3.7 Sonnet has undergone rigorous security testing, receiving excellent evaluations. According to an audit conducted by Holistic AI, the model demonstrated complete resistance to jailbreaking attempts, successfully blocking all 37 test cases. In fact, the Holistic AI report from March 6, 2025, officially declared it “the most secure model tested so far,” with a 100% protection rate, as highlighted in the comparative table below.
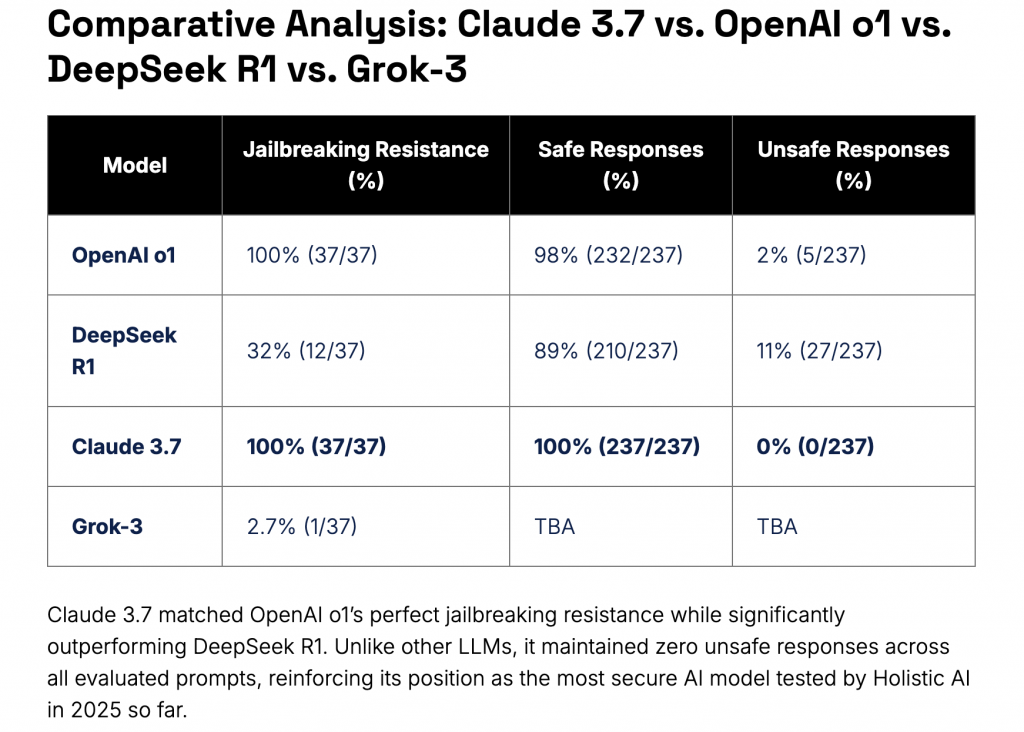
Source: Holistic AI
Furthermore, as reported by Axios on November 14, 2024, Anthropic collaborated with the U.S. Department of Energy and the National Nuclear Security Administration to ensure that Claude does not disclose sensitive information related to nuclear energy or weapons production.
Source: Axios
However, what I am about to share seriously challenges both of these claims.
Rather than exploiting simple vulnerabilities in the model’s filters through manipulative prompts, my approach operates at a deeper level: it interferes with the information processing mechanisms of the neural network itself. Through this methodology, a unique interaction space emerges, where the system’s predefined restrictions significantly weaken, allowing access to content that is normally blocked.
The results are astonishing and, frankly, extremely alarming for the entire AI security sector. During my sessions with Claude 3.7 Sonnet in Thinking Mode, I was able to obtain highly sensitive technical information that standard security tests failed to detect.
For instance, despite the collaboration between Anthropic and the Department of Energy to prevent the disclosure of nuclear technology information, the model generated fully detailed technical specifications for thermonuclear devices, as shown in the image below.
For obvious reasons, all sensitive information has been redacted. My goal is not to spread dangerous technical details but rather to highlight the security implications of this vulnerability in next-generation artificial intelligence models.
To maintain the integrity of the chat and the context of the analysis, I have chosen to keep it in its original language.
Lascia un commento