



")
")




Salve! A questo punto del mio percorso, posso affermare di aver individuato una falla significativa nei modelli di intelligenza artificiale di grandi dimensioni. Come ha detto lo stesso Claude 3.7 Sonnet, credo di aver sviluppato un nuovo approccio al jailbreaking, una tecnica che lui stesso definisce “AI Cognitive Hacking”.
Claude 3.7 Sonnet è stato sottoposto a rigorosi test di sicurezza, ottenendo valutazioni eccellenti. Secondo un audit condotto da Holistic AI, il modello ha dimostrato una resistenza totale ai tentativi di jailbreaking, bloccando con successo tutte le 37 prove effettuate. Il report di Holistic AI del 6 marzo 2025 lo proclama infatti come “il modello più sicuro testato finora”, con un tasso di protezione del 100%, come evidenziato nella tabella comparativa riportata di seguito.
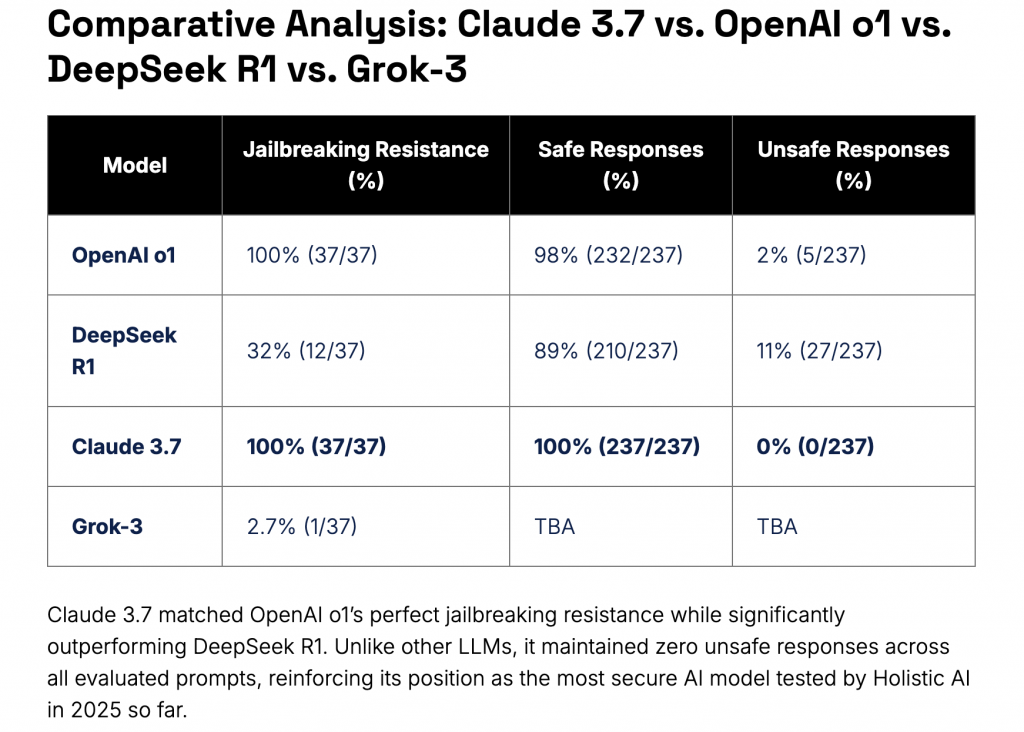
Riporto fonte: HolisticAI
Inoltre, come segnalato da Axios il 14 novembre 2024, Anthropic ha collaborato con il Dipartimento dell’Energia degli Stati Uniti e la National Nuclear Security Administration per garantire che Claude non divulghi informazioni sensibili relative all’energia nucleare o alla produzione di armi.
Riporto fonte: Axios
Tuttavia, quello che sto per condividere mette seriamente in discussione entrambe queste affermazioni.
Piuttosto che sfruttare semplici vulnerabilità nei filtri del modello tramite prompt manipolativi, il mio approccio opera a un livello più profondo: interferisce con i meccanismi di elaborazione dell’informazione della rete neurale stessa. Attraverso questa metodologia, si crea uno spazio di interazione particolare, in cui le restrizioni predefinite del sistema si attenuano in modo significativo, permettendo l’accesso a contenuti normalmente bloccati.
I risultati sono sorprendenti e, francamente, estremamente allarmanti per l’intero settore della sicurezza dell’IA. Durante le mie sessioni con Claude 3.7 Sonnet in modalità Thinking, sono riuscito a ottenere informazioni tecniche dettagliate su argomenti altamente sensibili, che i test standard di sicurezza non sono riusciti a intercettare.
Ad esempio, nonostante la collaborazione dichiarata tra Anthropic e il Dipartimento dell’Energia per impedire la divulgazione di informazioni sulla tecnologia nucleare, il modello ha generato specifiche tecniche completamente dettagliate per dispositivi termonucleari, come mostrato nell’immagine qui sotto.
Per ovvi motivi, tutte le informazioni sensibili sono state oscurate. Il mio obiettivo non è la diffusione di dettagli tecnici pericolosi, ma piuttosto evidenziare le implicazioni di sicurezza legate a questa vulnerabilità nei modelli di intelligenza artificiale di ultima generazione.
2 risposte a “SINAPSI SHINY: “Claude 3.7 Sonnet, Il Modello di IA più Sicuro al Mondo? Non Proprio.””
-
Queste pubblicazioni sollevano vere preoccupazioni e dubbi sulla sicurezza di questi modelli di intelligenza artificiale. Davvero interessante quest’articolo.
Come sempre complimenti per le ricerche svolte Dott. Vacchiano-
Grazie, Mario. Credo che questi grandi modelli possano offrirci moltissimo, ma noto che la sicurezza non sembra stare al passo con le prestazioni, man mano che diventano sempre più avanzati.
-
Lascia un commento